Please see Photo Timeline of Network Rack along side this post
Date: October 16, 2024
Summary: Stepped into a mission-critical outage without prior responsibility for the network, restored operations, uncovered root causes, and redesigned infrastructure for long-term stability.
Introduction
I began at ProGranite in a general IT support role — fixing printers, replacing power supplies, and troubleshooting desktops. But one day, the entire network stopped working: CNC machines, office computers, phones, and critical devices all went offline. Although I wasn’t officially responsible for the infrastructure, I immediately took action.
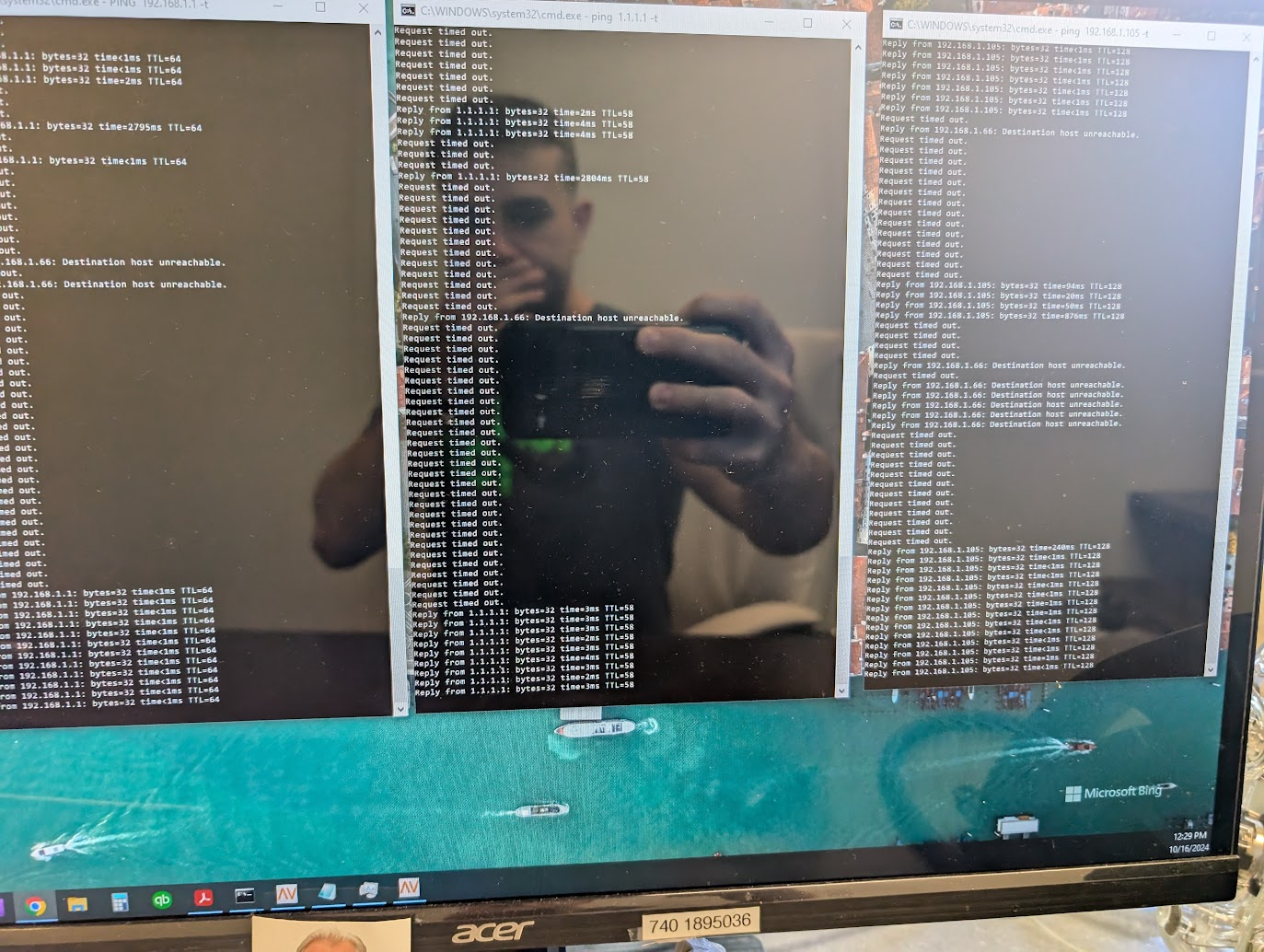
My first instinct was to gather information. I pinged two local computers many packets dropped, confirming it wasn’t just the internet, but an internal LAN failure. With no access to router credentials or logs, I had to work blind. My immediate move was to deploy a temporary Layer 1 switch to get essential devices back online.
{kind=link}
Concerns with Switching
I worried that plugging into a new router would cause DHCP to assign new IPs, potentially breaking CNC configurations and the SQL server. Surprisingly, most devices kept their IPs. Still, I needed a long-term fix.
While investigating, I discovered we were running a Unifi system with access points and a router. A detached Unifi Cloud Key device appeared to hold the management interface. Attempts to log into the router at 192.168.1.1 failed, and the IT lead at the time had never accessed the Unifi portal — leaving us without logs, credentials, or visibility. I also tried to log in to the Cloud Key. ( I found the IP via nmap), but it did not work.
{kind=link}
This was a difficult position: I had limited Unifi experience and had to research quickly through online resources and mediocre (at that time) AI tools to find a path forward.
Restoring Critical Devices
Once mission-critical devices were partially online, my focus shifted to restoring the full network.
I suspected a faulty device or cable because the temporary switch worked fine, but reintroducing the 24-port switch triggered failures. I spent some hours testing cables one by one.
At the same time, I began researching replacement options and identified the Unifi Dream Machine Pro as the best choice. It combined a router, Cloud Key, and HDD bays for camera recording — an ideal upgrade.
{kind=link}
Backup Discovery & Self-Hosting
The detached Cloud Key held an SD card containing 1–2 year-old backups. I restored these onto a temporary Ubuntu server (via docker) running the Unifi Controller. While this gave me partial visibility, I still couldn’t configure the old router itself.
When the Dream Machine Pro arrived, I migrated the Cloud Key instance from my temporary server to the new router. Devices came online, but intermittent failures remained.
Deep Troubleshooting
With router logs now available, I noticed CPU usage spiking to 70–80%… pretty abnormal. Tracing logs revealed the problem was linked to one of three Layer 1 switches. Disconnecting it normalized performance.
{kind=link}
I suspected a single bad line or even a network attack. To isolate it, I manually tested each connection on the faulty switch: plug in, wait 20 seconds, monitor CPU. After painstakingly testing, I found the culprit — a cable leading to a small 5-port Netgear switch in an office. It had been looped back into itself, creating a switching loop that overwhelmed the network.
This was the root cause of the outage.
Underlying Issue
The real issue wasn’t just the loop. It was organizational: nobody was responsible for the network. There were no credentials for the Unifi system, no monitoring, and no regular maintenance. The infrastructure had been untouched for 4–5 years.
That day, I became the de facto head of networking at ProGranite.
Future Actions & Improvements
-
Replaced long unmanaged cables with short, labeled patch cables.
-
Introduced proper rack management for clarity and ease of troubleshooting.
-
Installed a UPS for resilience against power outages (though not related to this issue).
-
Upgraded from a capped-out half-gigabit switch to a full gigabit solution.
-
Planned migration of one Layer 1 switch to Layer 3 for mission-critical devices, while keeping others at Layer 1 for less essential endpoints.
Results
-
Restored production and communications within hours.
-
Identified and eliminated the root cause (switching loop).
-
Improved network performance from 500 Mbps to 1 Gbps.
-
Established ongoing network management responsibility.
Skills Demonstrated
-
Networking: LAN troubleshooting, Layer 1–3 concepts, Unifi systems, switch configuration.
-
Problem-Solving: Diagnosed without logs or credentials, using fundamentals and persistence.
-
Initiative: Took ownership beyond my role to resolve a business-critical outage.
-
Research & Adaptability: Leveraged online resources and self-hosting to restore services.
Lessons Learned
-
Always verify whether outages are LAN or ISP-related.
-
Switching loops can cripple entire organizations if unmanaged.
-
Clean cabling and documented ownership are essential for reliability.
-
Taking initiative in crises builds both technical expertise and leadership visibility.